
Почему RAID 6 перестанет работать в 2019 году?
Несколько лет назад я предупреждал, что RAID 5 перестанет работать в 2009 году. Конечно, поставщики сетевых хранилищ не рекомендуют RAID 5. Они в настоящее время рекомендуют RAID 6, который защищает от отказов двух дисков в массиве. Но в 2019 году даже RAID 6 не будет защищать ваши данные. Вот почему.
RAID 6 = (RAID 5)2
Я писал, что и RAID 6 будет иметь ограниченный срок службы:
…RAID 6 через несколько лет даст вам не больше защиты, чем RAID 5 сегодня. Это не вина RAID 6. Наоборот, это из-за увеличения емкости дисков и неизменного количества неустранимых ошибок чтения.
Еще в декабре 2009 года инженер SUN, флэш архитектор и ZFS разработчик Адам Левенталь сделал анализ ожидаемого срока службы RAID 6 в качестве надежной стратегии защиты данных. Он опубликовал его в журнале ACM в статье “Тройная четность RAID и далее”, выдержки из которой я использую в этой статье.
Хорошая новость: Левенталь обнаружил, что уровень защиты RAID 6 будет так же хорош до 2019 года, как раньше был RAID 5.
Плохая новость: Левенталь предполагал, что диски являются более надежными, чем они есть на самом деле. Так что времени может быть даже меньше, если производители дисков не включатся в игру. И еще одна хорошая новость: одна из компаний уже имеет такой диск – и я скажу, кто это.
Суть проблемы
RAID массив – это контроллер (или программа), который объединяет группу дисков в один большой диск с помощью математических формул. Контроллер добавляет на диски дополнительные блоки контрольных сумм, таким образом чтобы потеря одного или двух дисков не приводила к потере информации (здесь и далее речь идёт о массивах RAID 5 и 6, а не RAID 0, 1 или 10). Контрольные суммы позволяют восстановить данные с выпавших из массива дисков, а при замене диска – реконструировать его содержимое.
Проблема с RAID 5 в том, что жесткие диски имеют ошибки чтения. В SATA дисках по спецификации допускается коэффициент неисправимых ошибок чтения (URE) на уровне 1014. Это означает, что один раз на 1014 бит диск просто не сможет прочитать данные.
1014 бит = 100000000000000/8/512 секторов = 24 414 062 500 секторов
реальный размер 2тб диска = 3 907 029 168 секторов
Когда в RAID 5 массиве из 7 дисков SATA по 2 ТБ один жесткий диск выходит из строя, у вас остается 6 дисков по 2ТБ. И пока контроллер RAID будет делать rebuild, весьма вероятно случится ошибка чтения (URE). После этой ошибки реконструкция RAID массива становится невозможна.
Вероятность того, что ребилд закончится успешно: (1 – 1 /(24 414 062 500)) ^ (6*3 907 029 168) ≈ 0,38
Итого существует 62% вероятность потерять данные из-за неисправимой ошибки чтения в массиве RAID5 из семи SATA дисков с одним сбойным диском.
RAID 6
RAID 6 решает эту проблему путем создания второй контрольной суммы. Вы можете потерять один диск, поймать ошибку чтения URE и все равно успешно пройти rebuild.
Вероятность того, что ребилд RAID6 на 7 SATA дисках закончится успешно: ((1 – 1 /(24 414 062 500)) ^ (6*3 907 029 168))+(1-(1 – 1 /(24 414 062 500)) ^ (6*3 907 029 168))*((1 – 1 /(24 414 062 500)) ^ (5*3 907 029 168)) ≈ 0,66
В чем проблема?
Проблем несколько:
- Долгое время восстановления массива (rebuild time). По мере роста емкости жестких дисков, увеличивается и время ребилда. Диск с данными со скоростью вращения 7200 оборотов в минуту пишет в среднем около 115 Мб/сек – и скорость записи снижается по мере наполнения диска – получается около 5 часов минимум, чтобы восстановить неисправный диск. Но большинство массивов не могут позволить ребилд на максимальной возможной скорости восстановления, поэтому на ребилд обычно уходит в 2-5 раз больше времени.
- Больше скрытых ошибок. Корпоративные массивы используют фоновые процедуры проверки (disk scrubbing), чтобы найти и исправить возможные ошибки диска, прежде чем они дадут о себе знать. Но, так как объем дисков увеличивается, то и disk scrubbing занимает больше времени. В большом массиве диск может месяцы не проверяться, а это означает больше ошибок при ребилде массива.
- Зависимость между сбоями дисков. Сторонники RAID предполагали, что отказы дисков – это независимые события. Но многолетний опыт показал, что это не так: сбой одного диска в массиве делает сбой другого диска намного более вероятным.
Упрощаем: большие диски = дольше rebuild + больше скрытых ошибок -> больше шансов сбоя RAID 6.
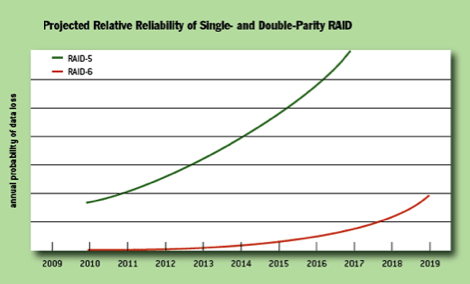 Прогноз Левенталя относительной надежности RAID с одинарной и двойной четностью
Прогноз Левенталя относительной надежности RAID с одинарной и двойной четностью
К 2019 году RAID 6 будет не более надежным, чем RAID 5 является сегодня.
Выводы
Для корпоративных пользователей этот вывод будет полезной информацией. В то время как тройная четность в массивах решит проблему защиты данных, придется идти на значительные компромиссы.
Рассмотрим 21-дисковый массив. Нужна неделя только на ребилд массива, так что в среднем массив всегда работает в ограниченном режиме восстановления (degraded rebuild mode). Полный переход на 2.5″диски? Функциональное устаревание текущих массивов стоимостью миллионы долларов?
Обычные пользователи могут расслабиться. Домашний RAID является изначально плохой идеей, лучше делайте чаще резервные копии с диска на диск и используйте сервисы онлайн бэкапа ценных данных.
И последний момент, Левенталь в своих расчетах использовал коэффициент ошибок дисков 10^16. Это верно для небольших, быстрых и дорогих корпоративных жестких дисков, но большинство обычных дисков SATA2 имеют коэффициент ошибок URE на порядок меньше – 10^14. За одним исключением: модель дисков WD20EADS серии Caviar Green от компании Western Digital по спецификации имеет коэффициент URE 10^15.





